Parallelization#
When programming custom algorithms in python, it can happen that our code becomes slow because we run a couple of nested for-loops. If the inner loops do not depend on each other, code can be parallelized and sped up. Note, we are parallelizing code on a central processing unit (CPU) don’t mix it up with GPU-acceleration that uses graphics processing units (GPUs).
See also
import time
import numpy as np
from functools import partial
import timeit
import matplotlib.pyplot as plt
import platform
We start with an algorithm that does something with an image at given pixel coordinates
def slow_thing(image, x, y):
# Silly algorithm for wasting compute time
sum = 0
for i in range(1000):
for j in range(100):
sum = sum + x
sum = sum + y
image[x, y] = sum
image = np.zeros((10, 10))
We now use timeit to measure how long the operation takes for processing a single pixel.
%timeit slow_thing(image, 4, 5)
3.3 ms ± 395 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
We now define the operation on the whole image and measure the time of this function.
def process_image(image):
for x in range(image.shape[1]):
for y in range(image.shape[1]):
slow_thing(image, x, y)
%timeit process_image(image)
353 ms ± 42.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
This function is quite slow and parallelization may make sense.
Parallelization using joblib.Parallel#
A simple and straightforward approach for parallelization is using joblib.Parallel and joblib.delayed.
from joblib import Parallel, delayed, cpu_count
Note the reverse writing of the for loops in the following block. The term delayed(slow_thing)(image, x, y) is technically a function call, that is not executed. Later, when the return value of this call is actually needed, then the actually execution will happen. See dask delayed for details.
def process_image_parallel(image):
Parallel(n_jobs=-1)(delayed(slow_thing)(image, x, y)
for y in range(image.shape[0])
for x in range(image.shape[1]))
%timeit process_image_parallel(image)
62.4 ms ± 218 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
A speedup of 7 is not bad. The n_jobs=-1 implies that all compute units / threads are used. We can also print out how many compute cores were used:
cpu_count()
16
For documentation purposes, we can also print out on what kind of CPU that algorithm was executed. This string might be more or less informative depending on what operating system / computer we are executing this notebook.
platform.processor()
'AMD64 Family 25 Model 68 Stepping 1, AuthenticAMD'
Benchmarking execution time#
In image processing, it is very common that execution time of algorithms shows different patterns depending on image size. We will now benchmark the algorithm above and see how it performs on differently sized images. To bind a function to benchmark to a given image without executing it, we are using the partial pattern.
def benchmark(target_function):
"""
Tests a function on a couple of image sizes and returns times taken for processing.
"""
sizes = np.arange(1, 5) * 10
benchmark_data = []
for size in sizes:
print("Size", size)
# make new data
image = np.zeros((size, size))
# bind target function to given image
partial_function = partial(target_function, image)
# measure execution time
time_in_s = timeit.timeit(partial_function, number=10)
print("time", time_in_s, "s")
# store results
benchmark_data.append([size, time_in_s])
return np.asarray(benchmark_data)
print("Benchmarking normal")
benchmark_data_normal = benchmark(process_image)
print("Benchmarking parallel")
benchmark_data_parallel = benchmark(process_image_parallel)
Benchmarking normal
Size 10
time 3.5427859 s
Size 20
time 13.8465019 s
Size 30
time 30.883478699999998 s
Size 40
time 55.4255712 s
Benchmarking parallel
Size 10
time 0.7873560999999967 s
Size 20
time 2.0985788000000127 s
Size 30
time 4.9782009000000045 s
Size 40
time 7.9171936000000045 s
plt.scatter(benchmark_data_normal[:,0] ** 2, benchmark_data_normal[:,1])
plt.scatter(benchmark_data_parallel[:,0] ** 2, benchmark_data_parallel[:,1])
plt.legend(["normal", "parallel"])
plt.xlabel("Image size in pixels")
plt.ylabel("Compute time in s")
plt.show()
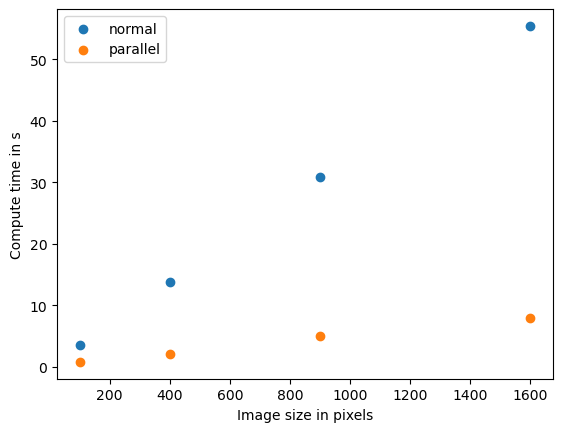
If we see this pattern, we speak of linear relationship between data size and compute time. Computer scientists use the O notation to describe the complexity of algorithms. This algorithm has O(n) and n represents the number of pixels in this case.
Quality assurance#
Note that in this section we only measured compute time of algorithms. We did not determine if the differently optimized versions of the algorithms produce the same result. Quality assurance is good scientific practice. The same is relevant in the context of GPU-acceleration and for example described in detail here.