Random forest decision making statistics#
After training a random forest classifier, we can study its internal mechanics. APOC allows to retrieve the number of decisions in the forest based on the given features.
See also
from skimage.io import imread, imsave
import pyclesperanto_prototype as cle
import pandas as pd
import numpy as np
import apoc
import matplotlib.pyplot as plt
import pandas as pd
cle.select_device('RTX')
<NVIDIA GeForce RTX 3050 Ti Laptop GPU on Platform: NVIDIA CUDA (1 refs)>
For demonstration purposes we use an image from David Legland shared under CC-BY 4.0 available the mathematical_morphology_with_MorphoLibJ repository.
We also add a label image that was generated in an earlier chapter.
image = cle.push(imread('../../data/maize_clsm.tif'))
labels = cle.push(imread('../../data/maize_clsm_labels.tif'))
fix, axs = plt.subplots(1,2, figsize=(10,10))
cle.imshow(image, plot=axs[0])
cle.imshow(labels, plot=axs[1], labels=True)

We previously created an object classifier and apply it now to the pair of intensity and label images.
classifier = apoc.ObjectClassifier("../../data/maize_cslm_object_classifier.cl")
classification_map = classifier.predict(labels=labels, image=image)
cle.imshow(classification_map, labels=True, min_display_intensity=0)
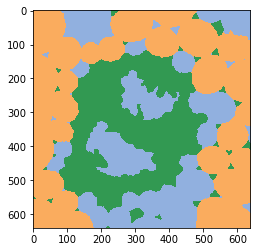
Classifier statistics#
The loaded classifier can give us statistical information about its inner structure. The random forest classifier consists of many decision trees and every decision tree consists of binary decisions on multiple levels. E.g. a forest with 10 trees makes 10 decisions on the first level, as every tree makes at least this one decision. On the second level, every tree can make up to 2 decisions, which results in maximum 20 decisions on this level. We can now visualize how many decisions on every level take specific features into account. The statistics are given as two dictionaries which can be visualized using pandas
shares, counts = classifier.statistics()
First, we display the number of decisions on every level. Again, from lower to higher levels, the total number of decisions increases, in this table from the left to the right.
pd.DataFrame(counts).T
| 0 | 1 | |
|---|---|---|
| area | 4 | 33 |
| mean_intensity | 32 | 44 |
| standard_deviation_intensity | 37 | 44 |
| touching_neighbor_count | 8 | 28 |
| average_distance_of_n_nearest_neighbors=6 | 19 | 34 |
The table above tells us that on the first level, 26 trees took mean_intensity into account, which is the highest number on this level. On the second level, 30 decisions were made taking the standard_deviation_intensity into account. The average distance of n-nearest neighbors was taken into account 21-29 times on this level, which is close. You could argue that intensity and centroid distances between neighbors were the crucial parameters for differentiating objects.
Next, we look at the normalized shares, which are the counts divided by the total number of decisions made per depth level. We visualize this in colour to highlight features with high and low values.
def colorize(styler):
styler.background_gradient(axis=None, cmap="rainbow")
return styler
df = pd.DataFrame(shares).T
df.style.pipe(colorize)
| 0 | 1 | |
|---|---|---|
| area | 0.040000 | 0.180328 |
| mean_intensity | 0.320000 | 0.240437 |
| standard_deviation_intensity | 0.370000 | 0.240437 |
| touching_neighbor_count | 0.080000 | 0.153005 |
| average_distance_of_n_nearest_neighbors=6 | 0.190000 | 0.185792 |
Adding to our insights described above, we can also see here that the distribution of decisions on the levels becomes more uniform the higher the level. Hence, one could consider training a classifier with maybe just two depth levels.
Feature importance#
A more common concept to study relevance of extracted features is the feature importance, which is computed from the classifier statistics shown above and may be easier to interpret as it is a single number describing each feature.
feature_importance = classifier.feature_importances()
feature_importance = {k:[v] for k, v in feature_importance.items()}
feature_importance
{'area': [0.1023460967511782],
'mean_intensity': [0.27884719464885743],
'standard_deviation_intensity': [0.34910187501327306],
'touching_neighbor_count': [0.09231893555382481],
'average_distance_of_n_nearest_neighbors=6': [0.1773858980328665]}
def colorize(styler):
styler.background_gradient(axis=None, cmap="rainbow")
return styler
df = pd.DataFrame(feature_importance).T
df.style.pipe(colorize)
| 0 | |
|---|---|
| area | 0.102346 |
| mean_intensity | 0.278847 |
| standard_deviation_intensity | 0.349102 |
| touching_neighbor_count | 0.092319 |
| average_distance_of_n_nearest_neighbors=6 | 0.177386 |