clEsperanto#
clEsperanto is a project between multiple bio-image analysis ecosystem aiming at removing language barriers. It is based on OpenCL, an open standard for programming graphics processing units (GPUs, and more) and its python wrapper pyopencl. Under the hood, it uses processing kernels originating from the clij project.
See also
GPU Initialization#
We’ll start with initializing checking out what GPUs are installed:
import pyclesperanto_prototype as cle
import matplotlib.pyplot as plt
import stackview
# list available devices
cle.available_device_names()
['NVIDIA GeForce RTX 3050 Ti Laptop GPU',
'gfx1035',
'cupy backend (experimental)']
# select a specific device with only a part of its name
cle.select_device("2080")
C:\Users\haase\mambaforge\envs\bio39\lib\site-packages\pyclesperanto_prototype\_tier0\_device.py:77: UserWarning: No OpenCL device found with 2080 in their name. Using gfx1035 instead.
warnings.warn(f"No OpenCL device found with {name} in their name. Using {device.name} instead.")
<gfx1035 on Platform: AMD Accelerated Parallel Processing (2 refs)>
# check which device is uses right now
cle.get_device()
<gfx1035 on Platform: AMD Accelerated Parallel Processing (2 refs)>
Processing images#
For loading image data, we use scikit-image as usual:
from skimage.io import imread, imshow
image = imread("../../data/blobs.tif")
imshow(image)
<matplotlib.image.AxesImage at 0x206d07ad0a0>

The cle. gateway has all methods you need, it does not have sub-packages:
# noise removal
blurred = cle.gaussian_blur(image, sigma_x=1, sigma_y=1)
blurred

|
cle._ image

|
# binarization
binary = cle.threshold_otsu(blurred)
binary

|
cle._ image

|
# labeling
labels = cle.connected_components_labeling_box(binary)
labels

|
cle._ image
|
# visualize results
imshow(labels)
C:\Users\haase\mambaforge\envs\bio39\lib\site-packages\skimage\io\_plugins\matplotlib_plugin.py:149: UserWarning: Low image data range; displaying image with stretched contrast.
lo, hi, cmap = _get_display_range(image)
<matplotlib.image.AxesImage at 0x206d2d6cb80>
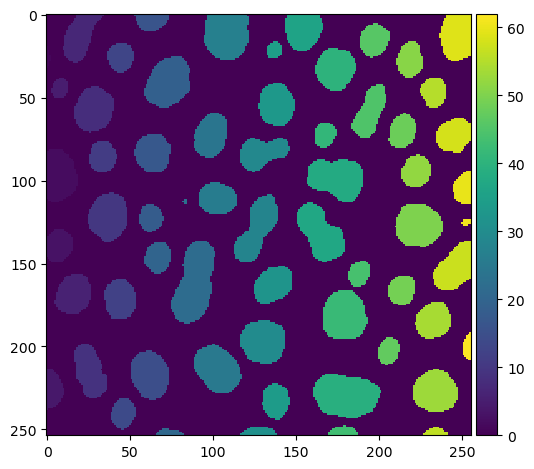
stackview also comes with an imshow function, that allows for example showing label images more conveniently:
stackview.imshow(labels)

One can also determine label edges and blend them over the image.
label_edges = cle.detect_label_edges(labels) * labels
stackview.imshow(image, continue_drawing=True)
stackview.imshow(label_edges, alpha=0.5)
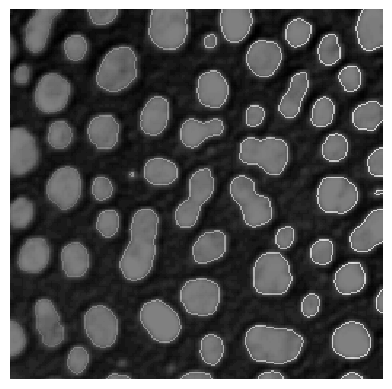
Therefore, it may make sense to increase the figure and combine multiple sub-plots
fig, axs = plt.subplots(1, 2, figsize=(12,12))
# left plot
stackview.imshow(image, plot=axs[0])
# right plot
stackview.imshow(image, alpha=0.5, continue_drawing=True, plot=axs[1])
stackview.imshow(label_edges, labels=True, alpha=0.5, plot=axs[1])

Some of these operations, e.g. voronoi_otsu_labeling are in fact short-cuts and combine a number of operations such as Gaussian blur, Voronoi-labeling and Otsu-thresholding to go from a raw image to a label image directly:
labels = cle.voronoi_otsu_labeling(image, spot_sigma=3.5, outline_sigma=1)
labels

|
cle._ image
|
Also, just a reminder, read the documentation of methods you haven’t used before:
print(cle.voronoi_otsu_labeling.__doc__)
Labels objects directly from grey-value images.
The two sigma parameters allow tuning the segmentation result. Under the hood,
this filter applies two Gaussian blurs, spot detection, Otsu-thresholding [2] and Voronoi-labeling [3]. The
thresholded binary image is flooded using the Voronoi tesselation approach starting from the found local maxima.
Notes
-----
* This operation assumes input images are isotropic.
Parameters
----------
source : Image
Input grey-value image
label_image_destination : Image, optional
Output image
spot_sigma : float, optional
controls how close detected cells can be
outline_sigma : float, optional
controls how precise segmented objects are outlined.
Returns
-------
label_image_destination
Examples
--------
>>> import pyclesperanto_prototype as cle
>>> cle.voronoi_otsu_labeling(source, label_image_destination, 10, 2)
References
----------
.. [1] https://clij.github.io/clij2-docs/reference_voronoiOtsuLabeling
.. [2] https://ieeexplore.ieee.org/document/4310076
.. [3] https://en.wikipedia.org/wiki/Voronoi_diagram
Interoperability#
In pyclesperanto, images are handled in the random access memory (RAM) of your GPU. If you want to use other libraries, which process images on the GPU, the memory must be transferred back. Usually, this happens transparently for the user, e.g. when using scikit-image for measuring region properties:
from skimage.measure import regionprops
statistics = regionprops(labels)
import numpy as np
np.mean([s.area for s in statistics])
333.77272727272725
If you want to explicitly convert your image, e.g. into a numpy array, you can do it like this:
np.asarray(labels)
array([[ 0, 0, 0, ..., 62, 62, 62],
[ 0, 0, 0, ..., 62, 62, 62],
[ 0, 0, 0, ..., 62, 62, 62],
...,
[ 0, 0, 0, ..., 0, 0, 0],
[ 0, 0, 0, ..., 0, 0, 0],
[ 0, 0, 0, ..., 0, 0, 0]], dtype=uint32)
Memory management#
In jupyter noteboooks, variables are kept alive as long as the notebook kernel is running. Thus, your GPU may fill up with memory. Thus, if you don’t need an image anymore, remove it from memory using del. It will then be remove from GPU memory thanks to pyopencl magic.
del image
del blurred
del binary
del labels